

When it comes to search engine optimisation, the importance of relevant keywords, site structure, appropriate tagging, backlinking and high quality content are just some of the major aspects. Chances are you’ve never really considered a lot about ‘Googlebot Optimisation’. Googlebot is Google’s official search bot (also known as a spider) that crawls the web and creates an index. The purpose of this bot is to crawl every single page it’s allowed access to and then add the page to the index.
While SEO focuses largely on the ability to optimise for user based queries, optimising your site for Googlebot is all about how well Google’s crawler can access your sites pages. Despite the differing objectives of these two processes, there’s still a lot of overlap. Think of a websites crawlability as the foundation of a website with good searchability.
Ensure Googlebot Is Allowed To Crawl & Index Your Pages
It doesn’t matter how great your content might be, if search engines are unable to crawl and index your websites pages, none of this will contribute towards your rankings. The first thing to check is the robots.txt file. Essentially, this file acts as the initial point of contact that search engines will come across when they crawl your website and identifies what parts should be crawled. The function itself acts by allowing or disallowing specific user agents.
In order to access the robots.txt file, you can add “/robots.txt” at the end of any chosen root domain. For example:
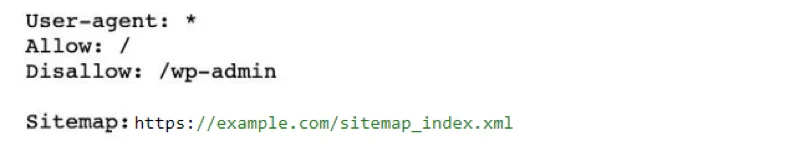
This example shows that the website is disallowing any URL’s that contain “/wp-admin” to not be crawled by search engines, as this is the WordPress backend of the website. There are many ways in which you can edit your robots.txt file. If you’re using WordPress, you can head into SEO → Tools → File Editor to make the necessary changes.
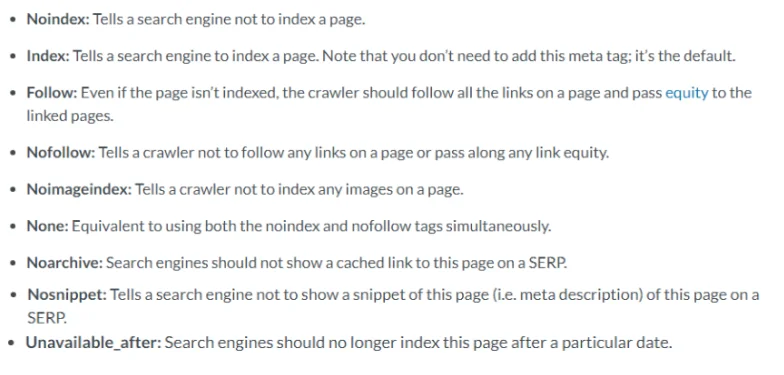
On the other hand, you also have something that’s called robot meta directives (also called tags). While the robots.txt file is responsible for giving bots suggestions on how to crawl a sites pages, the robots meta directives gives a more firm instruction on how to both crawl and index a pages content. The two types of existing robots meta directives are those that are part of the HTML page (meta robotstag) and those that the web server sends as HTTP headers (x-robots-tag). Below are a list of parameters that can be used with both a meta robots tag and in a x-robots-tag:
Checking Page Indexation Status
Once you’ve made sure that search engines can crawl your website, you’ll need to figure out if your pages are being correctly indexed.
Running a crawl is a great way to check the current state of your sites indexability. Screaming Frog proves to be an extremely useful tool for extracting URL specific data on indexation.
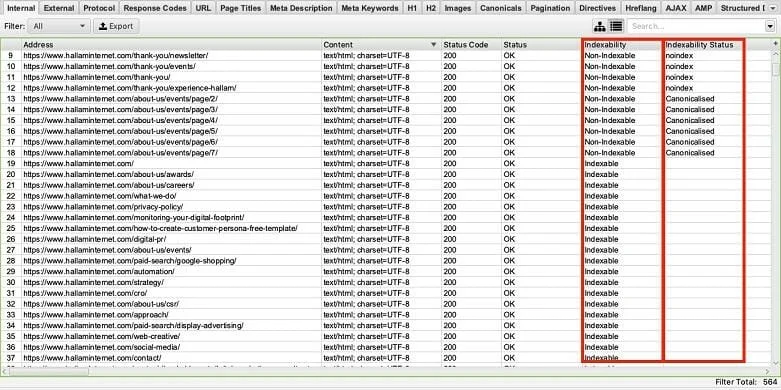
The indexability column will show your whether or not the URL is indexable, whilst the indexability status column displays the reasons as to why some URLs are non-indexable. If there is an evident difference in the number of URLs you have compared to those that are actually indexed, then you may want to ask yourself the follow:
- Are there existing duplicate pages and if so, should they be canonicalised?
- Is the HTTP version of the website still being indexed?
- Are there any considerable parts of the website not currently indexed but should be?
Revising Your Sitemap
Having a well structured and easy flowing sitemap is a must when it comes to optimising your website for search engine bots. First off, you want to make sure your XML sitemap is optimised as this is essentially a roadmap for search engines to crawl your website. Here are some of the followings things you want to review for an effective sitemap:
- Formatting (XML document)
- Solely include canonical URLs
- Exclude any ‘noindex’ URLs
- Ensure any new or updated pages are included
If you have plugins such as the yoast SEO plugin, this will automatically create an XML sitemap for your website. Other tools such as Screaming Frog will help identify all the URLs in your sitemap and those that are missing. The 3 major factors you want to look out for are:
- The structure is easy to follow
- Includes your primary pages
- Excludes any pages you don’t want indexed
Auditing Duplicate Content
The last step you want to check is whether or not your site contains duplicate content, which can have a very negative effective on SEO. However, despite being no official penalties for duplicate content, search engine bots don’t favour sites with recurring content as it may cause confusion as to what page to favour in the SERPs, which can cause a serious problem for your rankings. If a website has multiple duplicate URLs for example, search engine bots will only focus on one URL and the value associated with the ignored duplicates will be lost. On top of this, duplicate content does no good for user experience.
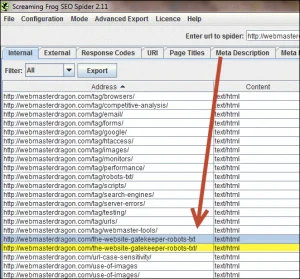
Use tools like Screaming Frog to identify duplicate content, such as URLs and pages. This will crawl your website and allow you to sort through the results by page title and URLs, allowing you to see any duplicate content.
Keeping Up With Mobile Compatibility
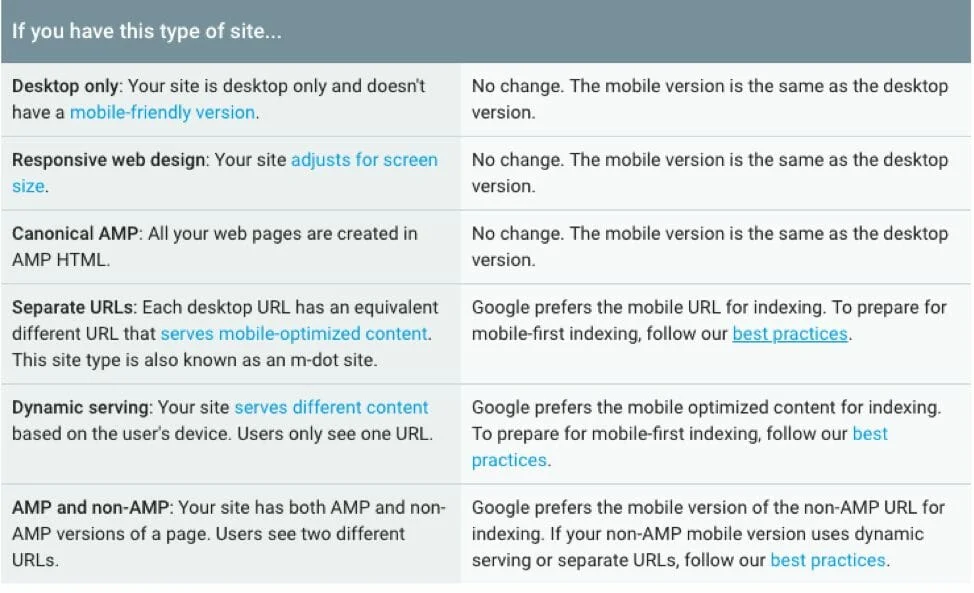
In 2018, Google revealed the release of mobile-first indexing and starting July 1st 2019, mobile-first indexing will be enabled by default for websites new or previously unknown to the Google Search. This essentially means that Google will predominantly use the mobile version of the website content for indexing and ranking, instead of making the desktop version of pages content the priority. The majority of online users now access Google Search through a mobile device, which makes sense for Google to announce such a dynamic change. See the following image for what this means for your site:
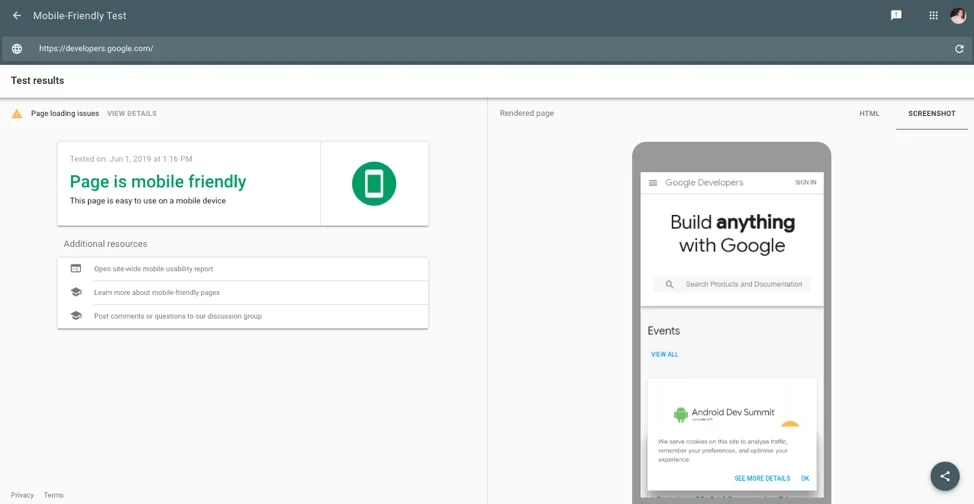
A great tool to check how responsive your website is for mobile users is Google’s Mobile-Friendly Test. Check your page by inputting your domain and it will show whether the page is mobile-friendly, with the option to view the advanced details if needed.
Always remember to complete an entire manual website audit through your own mobile device, picking up any ‘look and feel’ errors especially through the primary conversion paths. If you haven’t yet constructed your website to increase mobile compatibility, then it’s important to get on top of this as soon as possible.
These are the fundamentals aspects of optimising your website for crawling and indexing and as any digital marketer would know, these must be constantly monitored to ensure your website is sufficiently optimised.







