

The robots.txt file is sometimes overlooked when it comes to SEO. Nonetheless, it’s just as important as any other aspect to SEO. A robots.txt file has a range of uses, including telling search engines where to locate your sitemap and what pages to crawl and not to crawl. In more technical terms, the file is part of the robots exclusion protocol (REP), which is a group of web standards that regulate how robots crawl the web, access and index content, and serve that content up to users. This REP also include directives like meta robots, as well as ‘subdirectory-’, ‘page-’ or site-wide instructions on how search robots should treat certain links.
How To Create A Robots.txt File
Creating a robots.txt file for your website isn’t a difficult process, but it’s easy for mistakes to be made. This shouldn’t discourage you however from creating or updating a robots file for your site. If you’re unsure about how to first create your own robots.txt file check out this Google Support Page for an in depth guide, which takes you through the creation process and gives you everything you need to create your very own robots.txt file.
Adding robots.txt To Your Site
To locate your robots.txt file, type in your website domain URL followed by “/robots.txt”. For example: https://www.websitename.com/robots.txt. The is stored in the main folder or root directory of your site, which allows you to manage the crawling of each URL under your domain. Don’t forget that a robots file is case sensitive, so always ensure the file name is completely lower case. Here are a few examples of robots.txt in action:
Robots.txt file URL: www.websitename/robots.txt
Blocking all web crawlers from all content
User-agent: *
Disallow: /
Using this syntax lets all web crawlers know not to crawl any pages on www.websitename.com, which includes the homepage.
Allowing all web crawlers access to all content
User-agent: *
Disallow:
Using this syntax lets all web crawlers know to crawl any pages on www.websitename.com, which includes the homepage.
Blocking a specific web crawler from a desired folder
User-agent: Googlebot
Disallow: /example-subfolder/
This syntax lets Google’s crawler (user-agent name Googlebot) know not to crawl any pages that contain the URL string www.websitename.com/example-subfolder/.
Testing Your robots.txt File
The robots.txt is a plain text file, but it’s responsible for letting search engines know where they can and cannot go, which is extremely important. Once the files been added or has been updated, make sure to test it out so thats its working the way you want it to.
There are plenty of tools to test your robots file, including the Google file tester found in the old version of Search Console (which is still available). To do this, login to your websites Search Console, scroll to the bottom of the page and click on ‘Old Version’.
The next step is to locate the ‘robots.txt Tester’.
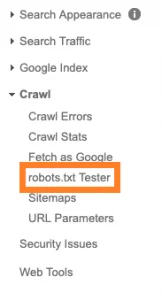
This will let you test your websites robots file, which is done by adding the code from your file to the provided box and selecting ‘test’.
![]()
If the test is successful, the test button should turn green and switch to ‘Allowed’, which confirms the file validity. It is now ready to be uploaded to your sites root directory.
Google September Update to robots.txt
Google recently made an announcement that quite a few changes are coming to how they understand unsupported directives in the robots.txt file. When the first of September hits this year, Google will come to a halt on supporting unpublished and unsupported rules in the robots exclusion protocol. Essentially, this means Google will no longer support the noindex directive within the robots.txt file.
If you have used this directive before to control how your websites being crawled or if you wish to prevent a portion of your website from being indexed, there are a number of effective alternatives you can use:
Disallow in robots.txt
Search engines can only index pages that they can find and crawl, so by blocking their access to certain pages from being crawled this means they won’t be indexed. The instruction for blocking crawls is called “disallowing”, which manages the behavior of certain user agents. The basic format for this is:
User-agent: [user-agent name]
Disallow: [URL string not to be crawled]
Together, these lines are considered to be an entire robots.txt file. However, the file can contain multiple lines of user agents and directives if you’re looking to block access to a variety of pages.
Password Protection
Creating password protection is a simple and great way to stop Google from viewing and crawling pages on your site or your site entirely (generally when a website is in development). Using a login to hide a page will normally remove it from Google’s index as they do not have the information required to access the desired page or site.
Status Codes
If you have any 404 pages and not ready to 301 redirect them but don’t want Google to index them, you can use a temporary 410 status code. For example, if you’re online site ceases to stop selling a specific product and no longer wants to be found in the SERPs for that product page, it’s a good idea to apply a 410 status code.
When the search engines come across a page with a 410, the URL will be dropped from the indexed as soon as they’re crawled and processed.
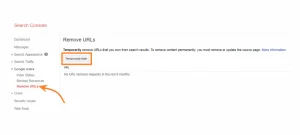
Search Console URL Tool
The Google Search Console offers a URL Tool that removes any requested URL from Google’s search results. This is classified as temporary as its only valid for approximately 90 days, after that, your URL can appear again in the SERPs.
Conclusion
Making any small changes can sometimes have a massive impact on your websites overall SEO, and the robots.txt file is one of those changes that can make a significant difference. So when search engine bots come across your website, they can spend their crawl budgets wisely, organising and displaying your SERPs content in the best way possible, which means you’ll be more visible.






